While our serverless applications grow day by day; the need to orchestrate our Lambda functions may become an issue. We might need to execute some functions sequentially and one of our functions might get output of another function as input. Similarly, some functions might require to be executed in parallel. In these cases, AWS Step Functions can help us to coordinate our Lambda executions as components of our distributed applications and microservices.
In this blog post, I will make an introduction to AWS Step functions with a simple case. I will try to show how we can define sequential and parallel executions, as well as intermediary states to transform one state’s output to pass another state as input.
AWS Step Functions Components
AWS Step functions service is based on tasks and state machines concepts. Using CloudFormation or AWS Console, we can define our state machines in JSON format using Amazon States Language. In this document, we can create an entry state, intermediary states and a final state. While our state machine can have only one state to be executed, it can also have multiple states in sequential or parallel.
Each state can have a different type:
Tasktype states execute a Lambda function or defines a worker process as anactivity. Activities are custom programs that performs polling for available states waiting for execution.Passtype states do nothing but can be used in debugging or transforming its inputs to the next state as output. I will show an example for the later one.Choicetype states can make decisions according to input values and decide which state to execute next.Waittype states are used for just waiting before continueing with the next state.Succeedstate can be used to stop the state machine successfully. They can be useful withChoicetype states for ending the process if certain conditions are met.Failtype states can be used to stop out state machine with failures. Again, they can be used withChoicestates.Paralleltype states are used to define multiple state components to be executed in parallel. These parallel states can consist of a single state or multiple sequential or parallel sub-states.
State machines start with an input and passes it to the first state. Then, every state gets the output of the previous state as input. As might be expected, parallel states take the same input from the previous state executed.
In this post, I will show examples for running Lambda functions sequentially and in parallel. This means that we will use Task and Parallel state types. I will also use Pass states to show how we can transform outputs of the previous states and pass as inputs to next.
Example Case: Moving a Recipe Between Users in Database and Re-indexing in Elasticsearch Using Step Functions
Please let me describe a case for demonstration. Let’s assume that we have a recipe sharing web application (such as Pişirpaylaş) and for some reason, we need to move one recipe to another user. After the move, we need to re-index this recipe in our Amazon Elasticsearch cluster, as well as its previous and new owner users.
While we can do this in one Lambda function, it would not be a best practice because of the complexity of the function and reusability of the components. One Lambda function should do one well-defined task. Besides, we might need some of the features later in different cases, right?
Then we will have these Lambda functions in a basic setting:
Move Recipe: A recipe move function that moves the recipe from one user to another in our database, which is Amazon Aurora.Input:
- id: Id of the recipe
- user_id: Id of the new owner user
Output:
- id: Id of the recipe
- old_user_id: Id of the previous owner of the recipe
- new_user_id: Id of the new owner of the recipe
Index Recipe: A recipe indexing function that reads a recipe’s data from the database and indexes in Amazon Elasticsearch cluster. It gets only one input: id of the recipe inidfield.Index User: A user indexing function that reads a user’s data from the database and indexes in Amazon Elasticsearch cluster. This function also gets only one input: id of the user inidfield.
I prefer to define different functions for indexing different types of documents in Elasticsearch, because of different mappings they have. Anyway, I will not dive into details of accessing Amazon Elasticsearch in AWS Lambda functions in this post.
Let’s construct our state machine one by one.
A State Machine with Only One State
As a start, I will only define one state machine that gets ids of the recipe and the new owner and executes Move Recipe Lambda function.
Our JSON definition will be as below.
{
"Comment": "Pisirpaylas recipe moving state machine",
"StartAt": "MoveRecipeDb",
"States": {
"MoveRecipeDb": {
"Type": "Task",
"Resource": "<The ARN of 'Move Recipe' Lambda function>",
"End": true
}
}
}As you can see, states of our state machine are defined in States field. Each state should have a unique name. The entry point of our state machine is MoveRecipeDb state which is defined by using StartAt field. This means that, the input supplied to the state machine will be passed to this state and execution will start. For now, we end the state after MoveRecipeDb state by defining an End attribute with true value.
We can visualize our state machine on AWS console as below.

A State Machine with Two States Executed Sequentially
Let’s make some changes in our state machine and execute Index Recipe function after MoveRecipeDb state.
{
"Comment": "Pisirpaylas recipe moving state machine",
"StartAt": "MoveRecipeDb",
"States": {
"MoveRecipeDb": {
"Type": "Task",
"Resource": "<The ARN of 'Move Recipe' Lambda function>",
"Next": "EsIndexRecipe"
},
"EsIndexRecipe": {
"Type": "Task",
"Resource": "<The ARN of 'Index Recipe' Lambda function>",
"End": true
}
}
}We removed End attribute in MoveRecipeDb state and defined a new attribute Next which points to our new state, EsIndexRecipe. This means that after MoveRecipeDb state finishes, our state machine will execute EsIndexRecipe task by providing the output produced by MoveRecipeDb as input. If you can recall, Move Recipe function passes id of the recipe to its output in id attribute. Therefore, Index Recipe Lambda function will execute successfully.
It will also get old_user_id and new_user_id attributes as they are outputs of the previous function. However, as long as our Lambda function discards them, they will not impose any problem.
Our state machine visual on AWS console becomes as below.

A State Machine with Sequential and Parallel States
We need to index old and new owner of the recipe in our Elasticsearch cluster as well as the recipe moved. We should achieve this in the efficient way possible. In previous case, sequential definition was meaningful, because Index Recipe function should be called after Move Recipe function. However, Index Recipe and Index User are independent functions and they should not know anything about eachother. In other words, they should remain as black boxes. Besides, Index User should be used for indexing both old and new users. All of the indexing should be excuted after MoveRecipeDb state. Wouldn’t it be perfect if we can make these executions in parallel?
We can achieve this using Parallel states. A Parallel state consist of multiple states defined in Branches attribute which are executed in parallel.
{
"Comment": "Pisirpaylas recipe moving state machine",
"StartAt": "MoveRecipeDb",
"States": {
"MoveRecipeDb": {
"Type": "Task",
"Resource": "<The ARN of 'Move Recipe' Lambda function>",
"Next": "EsIndexParallel"
},
"EsIndexParallel": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "EsIndexRecipe",
"States": {
"EsIndexRecipe": {
"Type": "Task",
"Resource": "<The ARN of 'Index Recipe' Lambda function>",
"End": true
}
}
},
{
"StartAt": "EsIndexOldUser",
"States": {
"EsIndexOldUser": {
"Type": "Task",
"Resource": "<The ARN of the 'Index User' Lambda function>",
"End": true
}
}
},
{
"StartAt": "EsIndexNewUser",
"States": {
"EsIndexNewUser": {
"Type": "Task",
"Resource": "<The ARN of 'Index User' Lambda function>",
"End": true
}
}
}
]
}
}
}We changed MoveRecipeDb state’s next state as EsIndexParallel. EsIndexParallel state starts EsIndexRecipe, EsIndexOldUser and EsIndexNewUser states in parallel.
The state diagram becomes as below.

Now let’s run this using a valid recipe id and user id to move and visualize in AWS Console.

Why did this happen? Remember, all our indexing functions receives output of the MoveRecipeDb state which is similar to below:
{
"id": "933",
"old_user_id": "16",
"new_user_id": "3"
}Here, id is the id of the recipe moved. We should have provided old_user_id to the EsIndexOldUser state as id parameter. Luckily, a user with id 933 did not exist in our system and our Lambda function failed and notified us about the problem.
Similarly, new_user_id should have been supplied as id parameter in third branch, EsIndexNewUser. It did not fail, because it was cancelled. It was basically same as EsIndexOldUser.
Let’s look at the execution details on AWS Console to understand better.

Although EsIndexRecipe seems cancelled, actually it finished successfully, because it started before the failure of EsIndexOldUser. We can see this in CloudWatch Logs. However, even if schedulled, EsIndexNewUser did not start before the failure of EsIndexOldUser and it was really cancelled before execution.
A Complete State Machine with Input Transformation
Now, let’s solve the input parameter problem of the previous section by defining intermediary Pass states:
{
"Comment": "Pisirpaylas Move Recipe state machine parallel indexing",
"StartAt": "MoveRecipeDb",
"States": {
"MoveRecipeDb": {
"Type": "Task",
"Resource": "<The ARN of 'Move Recipe' Lambda function>",
"Next": "EsIndexParallel"
},
"EsIndexParallel": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "EsIndexRecipe",
"States": {
"EsIndexRecipe": {
"Type": "Task",
"Resource": "<The ARN of 'Index Recipe' Lambda function>",
"End": true
}
}
},
{
"StartAt": "TransformOldUser",
"States": {
"TransformOldUser": {
"Type": "Pass",
"InputPath": "$.old_user_id",
"ResultPath": "$.id",
"OutputPath": "$",
"Next": "EsIndexOldUser"
},
"EsIndexOldUser": {
"Type": "Task",
"Resource": "<The ARN of 'Index User' Lambda function>",
"End": true
}
}
},
{
"StartAt": "TransformNewUser",
"States": {
"TransformNewUser": {
"Type": "Pass",
"InputPath": "$.new_user_id",
"ResultPath": "$.id",
"OutputPath": "$",
"Next": "EsIndexNewUser"
},
"EsIndexNewUser": {
"Type": "Task",
"Resource": "<The ARN of 'Index User' Lambda function>",
"End": true
}
}
}
]
}
}
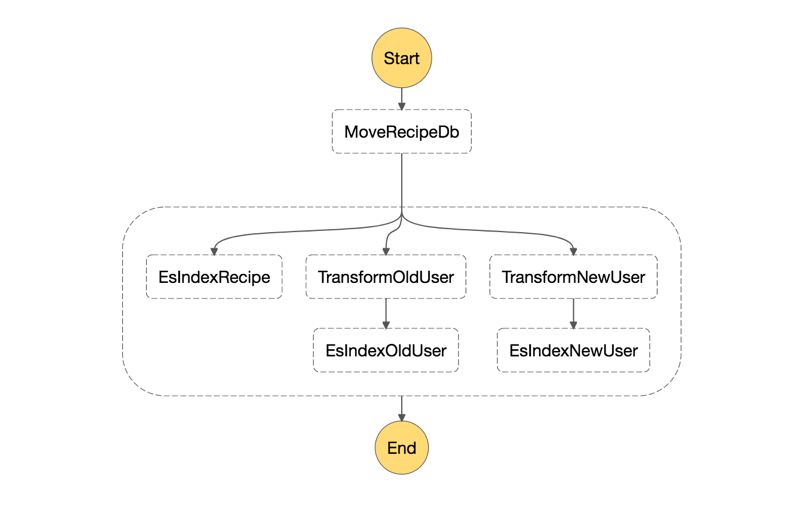
}And the diagram becomes as below:

As you can see from the JSON document, we defined two intermediary starter states in user indexing branches.
TransformOldUser state is a Pass state. It gets old_user_id as JSON path variable in InputPath attribute and places it in id attribute of the result using ResultPath attribute. Lastly, OutputPath merges ResultPath with input variables, producing the final output as below:
{
"id": "16",
"old_user_id": "16",
"new_user_id": "3"
}This will be input to EsIndexOldUser state.
Similarly, TransformNewUser state does the same thing for new_user_id and its output becomes:
{
"id": "3",
"old_user_id": "16",
"new_user_id": "3"
}As our Index User Lambda function only cares for id attribute, it will discard old_user_id and new_user_id attributes. Let’s make a final execution:

Hopefully, we provided correct inputs to Index User Lambda functions. We also reused this Lambda function for two branches without making any specific modifications that will only be meaningful just for this case.
As you can see below, EsIndexOldUser and EsIndexNewUser states which use the same Lambda function were executed in parallel. This is awesome for scalability and reusability.

Conclusion
In this blog post, I made an introduction to AWS Step Functions which provide an efficient way to orchestrate our Lambda functions. I also tried to show how we can transform inputs between state executions which allowed us to reuse the same Lambda function in parallel states. I hope this post gave you an idea about how you can use Step Functions in your projects.
In future posts, I will dive into more details about AWS Step Functions such as API Gateway integrations and failure retry mechanisms.
Thanks for reading!





